
Real Life System Design: Scaling Push Messaging for Millions of Devices @Netflix
A great talk on Background Push Message Infrastructure

What is Push?
PUSH = “PERSIST UNTIL SOMETHING HAPPENS”
PERSIST = Through persistent connection
SOMETHING HAPPENS = Something happens at the server side (some new data is generated by some action) and it’s pushed to the clients.
Push notification is used to push information to client application in the background through persistent connection. The information could be a list containing updated recommendations for the user, a simple notification etc.
Netflix calls it a Zuul push notification which is pretty similar to FCM notification in Android or Apple push notification except Zuul notifications work across devices (laptops, game consoles, smart TVs, mobiles etc).
Zuul Push notification uses Websocket and SSE (Server Sent Events) to achieve this.
Zuul Push is not a single component, it’s a complete push messaging architecture made up of different components.
High Level Architecture
Let’s take a look at different components of the Zuul Push Messaging Architecture.
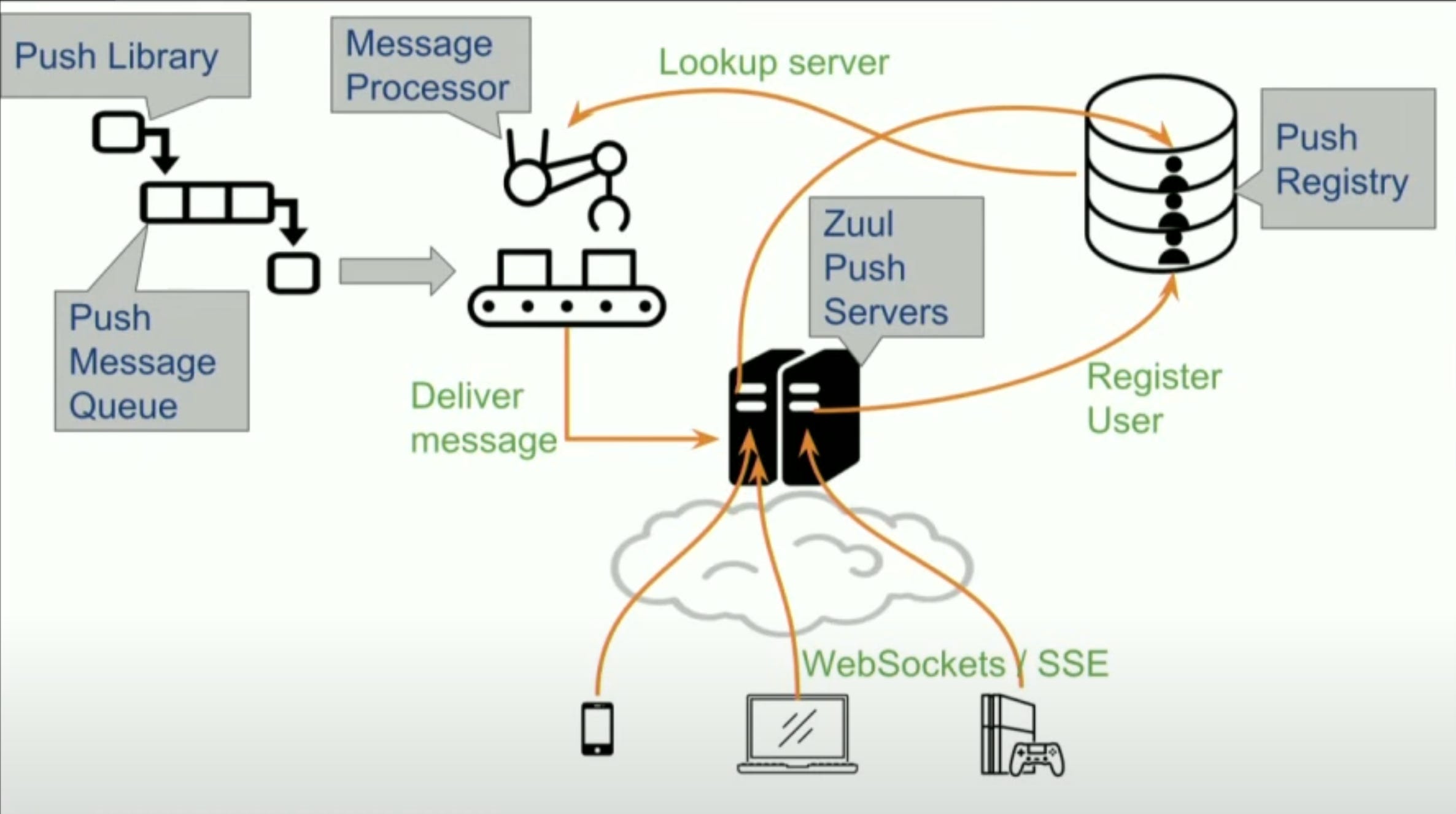
Zuul Push Servers: These servers sit at the edge, they accept client connections, clients maintain persistent Websocket / SSE connection to these edge servers on which they receive the notifications.
Push Registry: A central registry which maintains mapping of which clients are connected to which Zuul push edge servers.
Push Library: The backend applications which want to push notifications to clients use this library and makes a one liner call in code to push the message. The clients don’t need to know anything about how the infrastructure works, they just send the messages.
Push Message Queue: The queue decouples the push messaging infrastructure from the clients and allow the infrastructure to process messages asynchronously.
Message Processor: These are processes which read messages from the queue, does a lookup in the push registry to figure out whether the recipient client is currently connected to any edge server, if connected, the message is delivered, else the message is dropped.
Deep Dive
Zuul Push cluster containing multiple Zuul Push servers (edge servers) are the biggest piece in the infrastructure and it handles millions of persistent connections (at the time of the talk in 2018, the cluster handles 10 million concurrent connections at peak).
Zuul Push server is based on Zuul Cloud Gateway, the API Gateway which fronts all the HTTP traffic that comes into Netflix ecosystem. At the time of the talk in 2018, the API Gateway handles more than 1 million HTTP requests per second. It works on non-blocking async IO.
But, why is non-blocking async IO required? According to the old C10K Challenge, you have to support 10K concurrent connections in a single server - this essentially means that a server has to support not just 10K but tens of thousands of connections in order to support millions of concurrent open connections in aggregate, that’s a fundamental requirement for Zuul Push like system.
Don’t traditional HTTP servers scale to 10K concurrent connections?
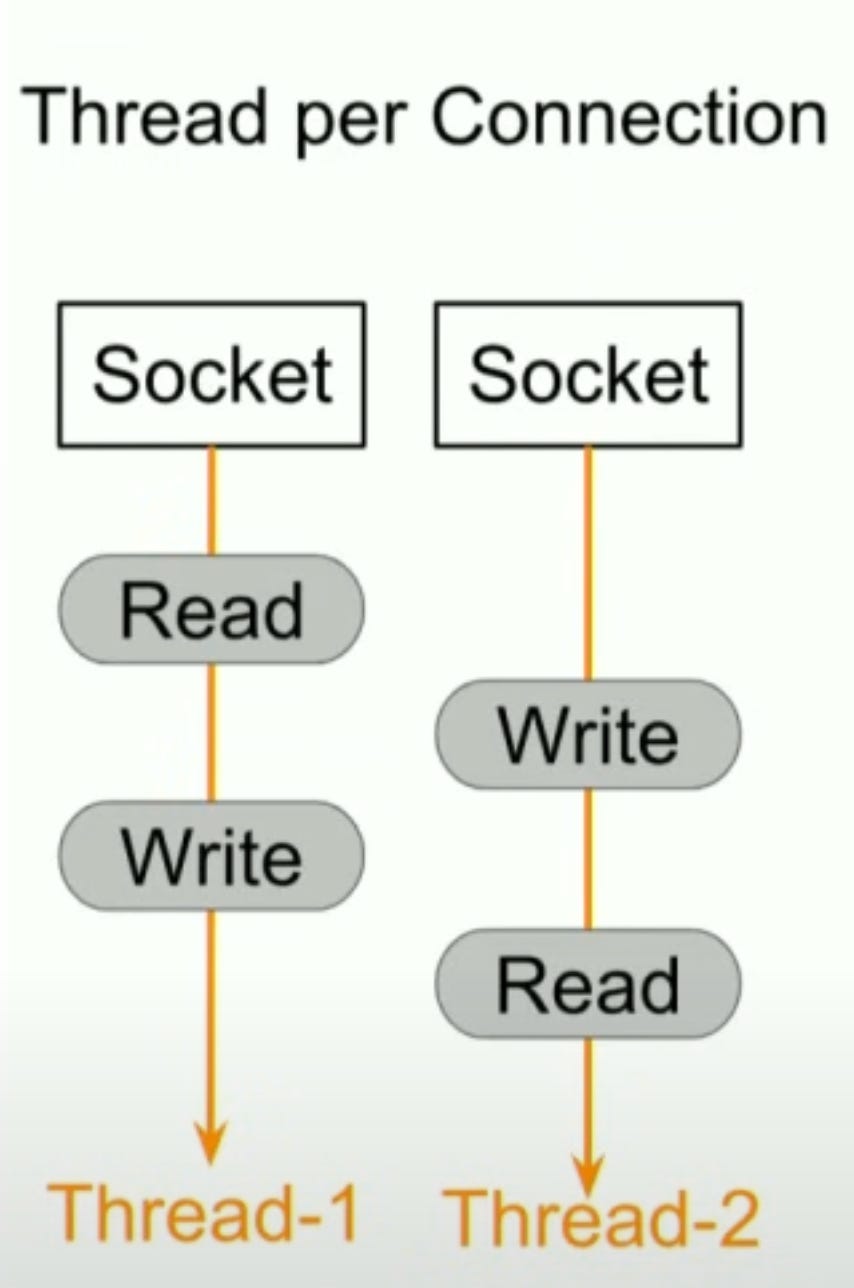
Traditional servers use one thread per connection model. So, there are some problems:
To support 10K thread stacks for 10K threads, it will require large memory.
CPU will be used inefficiently to context switch among multiple threads.
Thus, it’s difficult to scale traditional servers to thousands of connections per machine.
Async IO follows a different programming model.
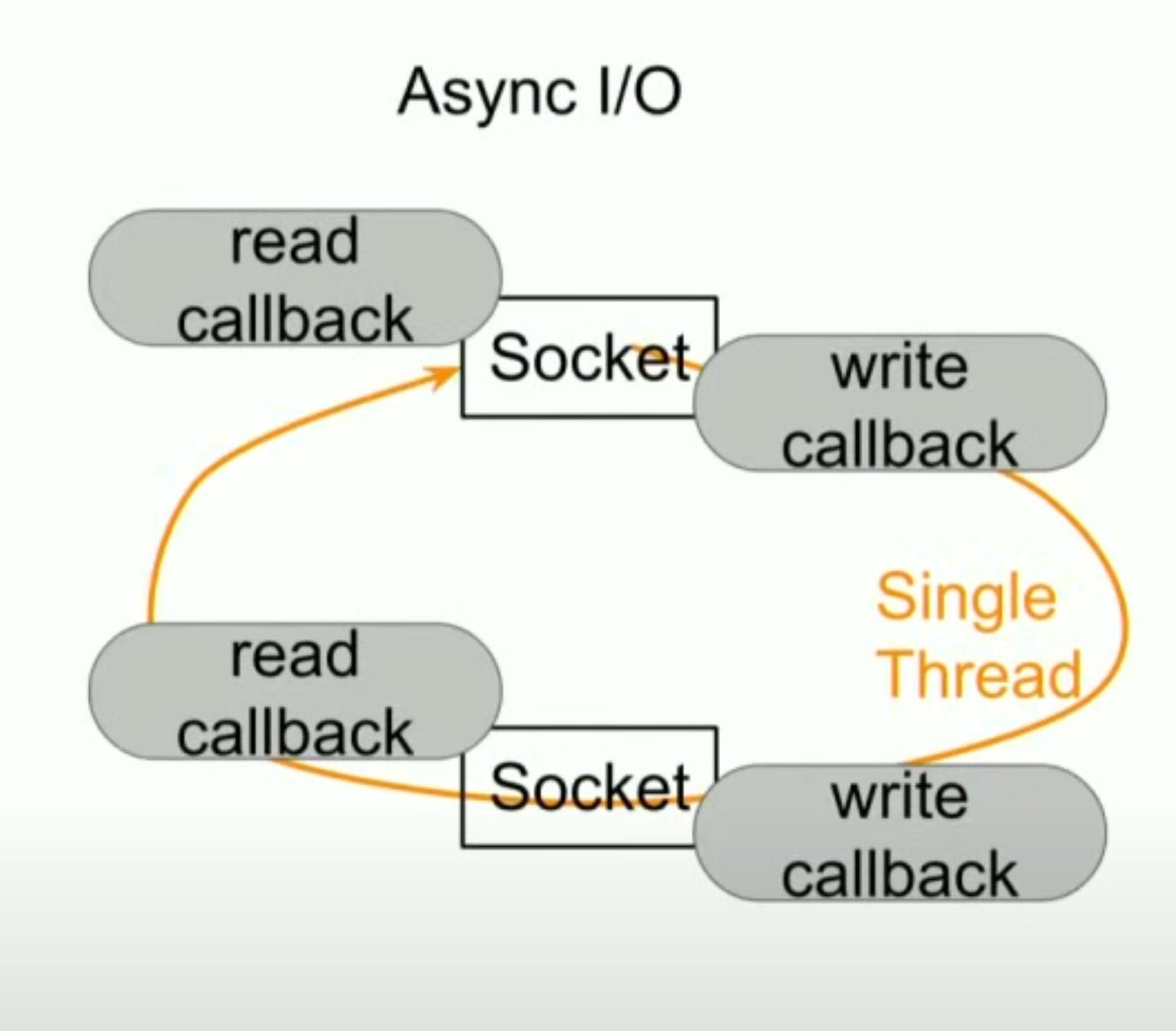
It uses operating system provided multiplexing IO primitives like kqueue, epoll etc to register read or write callbacks on open connections in a single thread. When a connection is ready to read or write, its corresponding callback is invoked in the same thread. Hence, there is no need of as many as threads as open connections. Thus, it scales much better.
The tradeoff here is the application is more complicated now. Because now the developer is responsible for maintaining state of all the connections in the code, the thread stack won’t do so as it’s shared among all connections now. It’s typically done by some kind of event or state machine in the code.
Netflix uses Netty to do asynchronous non-blocking IO. It’s open source, written in Java and it’s used in many popular open source Java projects like Cassandra and Hadoop. It’s a time tested solution.
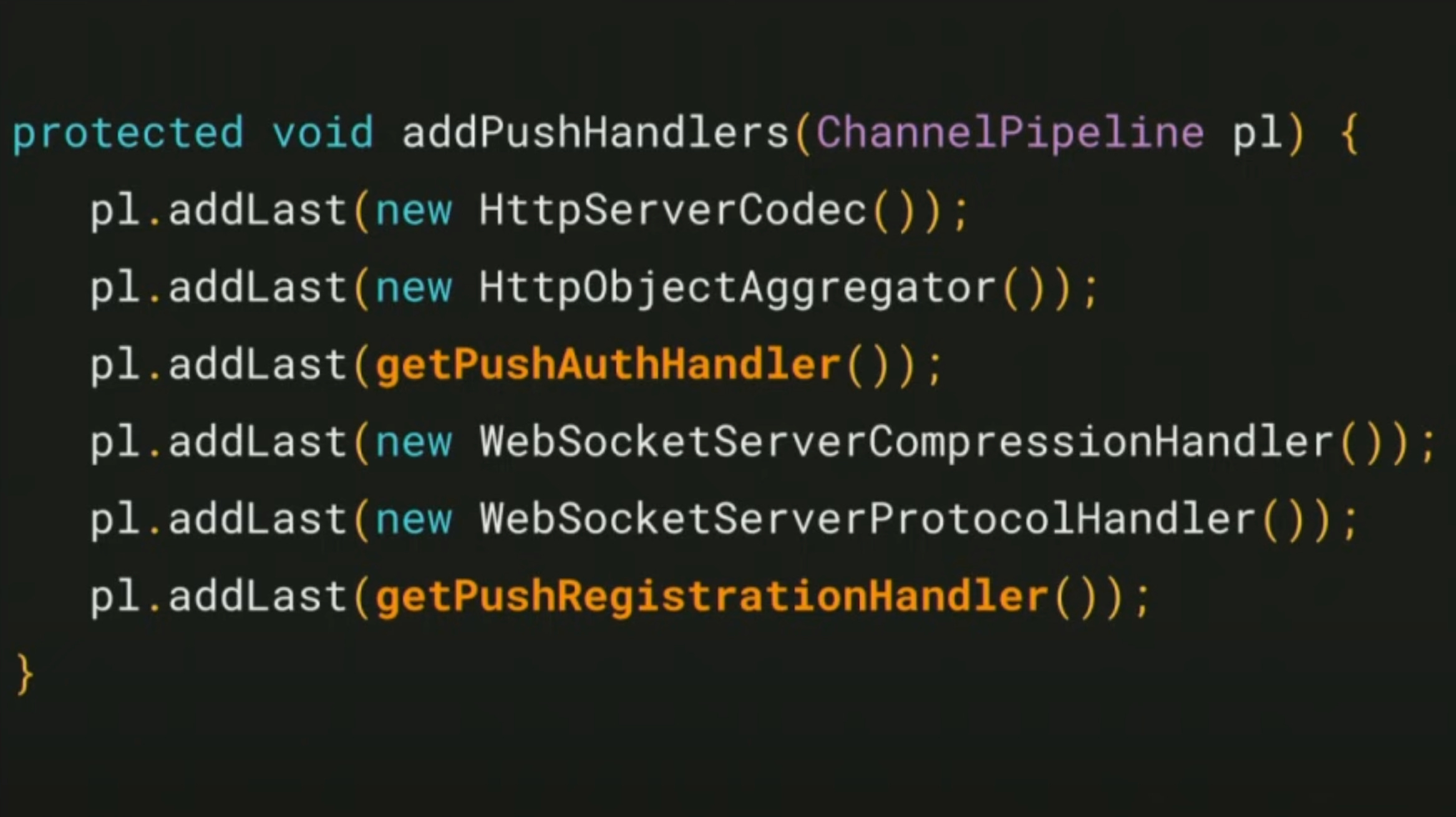
The above code shows a high level view of Netty configuration. The code in yellow indicates that you can plug-in your own auth handler and push registration handler to Netty. Rest of the things like HttpServerCodec , WebSocketProtocolHandler etc are off the shelf HTTP and WebSocket protocol parsers / support from Netty.
Each client that connects to a Zuul Push server for the first time has to authenticate itself using Cookies, JWT or any other scheme through custom authentication facility. There are provisions to do that.
Push Registry
A registry where serialised client auth information is stored. Client user id, device id or a combination of both can be used as a key which maps to the push server host ip and port.
The data store can be anything as long as it has the following characteristics:
Low read latency: A client writes just only once to the data store when it connects first, but the data is read multiple times every time some backend server wants to send a notification to the client. So, it’s very important to have low read latency, though write latency can be compromised a bit.
Record Expiry: The data store should support per record expiry or
TTL. It’s required in case a push server crashes or a client crashes unexpectedly or the clients don’t disconnect from the server in a clean way, there should be some mechanism to clean up the phantom registration records.Sharding: Required for high availability and high throughput.
Replication: Required for fault tolerance.
Some good choices of push registry are Redis, Cassandra, AWS DynamoDB.
Netflix uses Dynomite. It’s a wrapper over Redis that provides auto sharding, read/write quorum, cross-region replication etc.
Message Processing
This component facilitates message routing, queuing and delivery on behalf of the senders.
Netflix uses Kafka as queuing mechanism.
Most of the push message senders rely on
Fire-And-Forgetdelivery semantics.The senders who care about the final result of the delivery, they can get the delivery status either by subscribing to the push delivery status queue or they can read it from a hive table in batch mode where every push message delivery is logged.
Cross-Region Replication
Netflix runs in three different regions of Amazon cloud. Backend push message senders typically have no idea to which region the intended receiver client might be connected.
The Zuul Push infrastructure relies on Kafka message queue replication to route the messages to the appropriate region. Under the hood, Kafka message queue replication replicates the messages to all the three regions.
Priority
In practice, Netflix found that they could use the same message queue (topic) for all sorts of messages and they would be still below the message delivery SLA.
But using a single message queue causes priority inversion → a high priority message might wait behind a bunch of a low priority messages.
Different message queues dedicated for message with different priorities ensure that priority inversion would never happen.
Multiple message queues are used in parallel to increase the message processing throughput.
Message processors are based on internal stream processing engine called Mantis, it’s somewhat like Apache Flink. It uses Mesos container management system which makes it easy for them quickly spin up bunch of message processors if the processing the message backlog falls behind. It comes with a out-of-the-box support for scaling the number of message processor instances based on how many messages are waiting in the push message queue. This feature helps the system meet delivery SLA under a wide variety while staying resource efficient.
Operating Zuul Push
Persistent connections (long lived stable connections) make Zuul push servers stateful.
Such connections are great from client’s perspective as they improve the client experience.
Terrible for quick deploy or rollback from system’s perspective. Example: If you deploy a new build to a new cluster, clients connected to the old cluster don’t get auto-migrated to the new cluster. The system has to force the migration in some way. But if the migration is forced, all the clients will swamp to the new cluster together resulting into thundering herd - a large number of client connecting to the same service at the same time. This results into a big spike in incoming traffic which is order of magnitude higher than the usual traffic. Thundering herd has to be handled carefully in a resilient and robust system.
The way to handle this scenario is to limit the client connection lifetime (typically between 25 to 30 minutes). The clients must be coded in such a way that they should be added to connect back to the server when they lose connection. Taking advantage of this feature, Netflix initially chose to auto-close the connections from the server side periodically. So, when the client connects back, most likely due to load balancing, it would land in a new server. This time period is tuned carefully to get a balance between client efficiency and stickiness to the server.
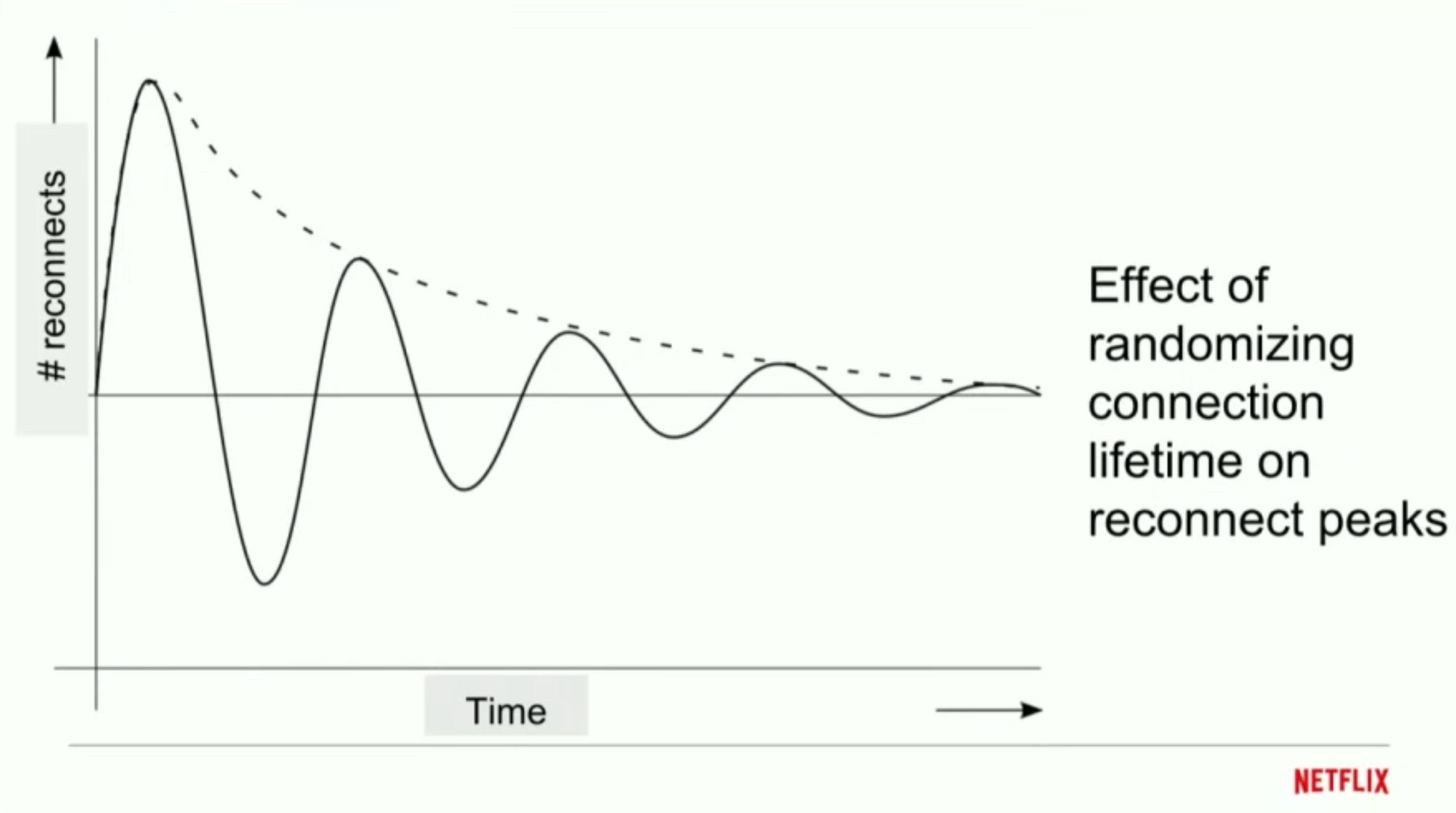
Also each connection’s life time is randomized to further minimize the possibility of thundering herd. If the connection timeout is same for every connection, in a case where a lot of connections disconnect from a server due to a network blip at the same time, they would most likely reconnect back to the system again almost at the same time and this will go on forever whenever a network blip happens - that’s recurring thundering herd. Randomization prevents that problem.
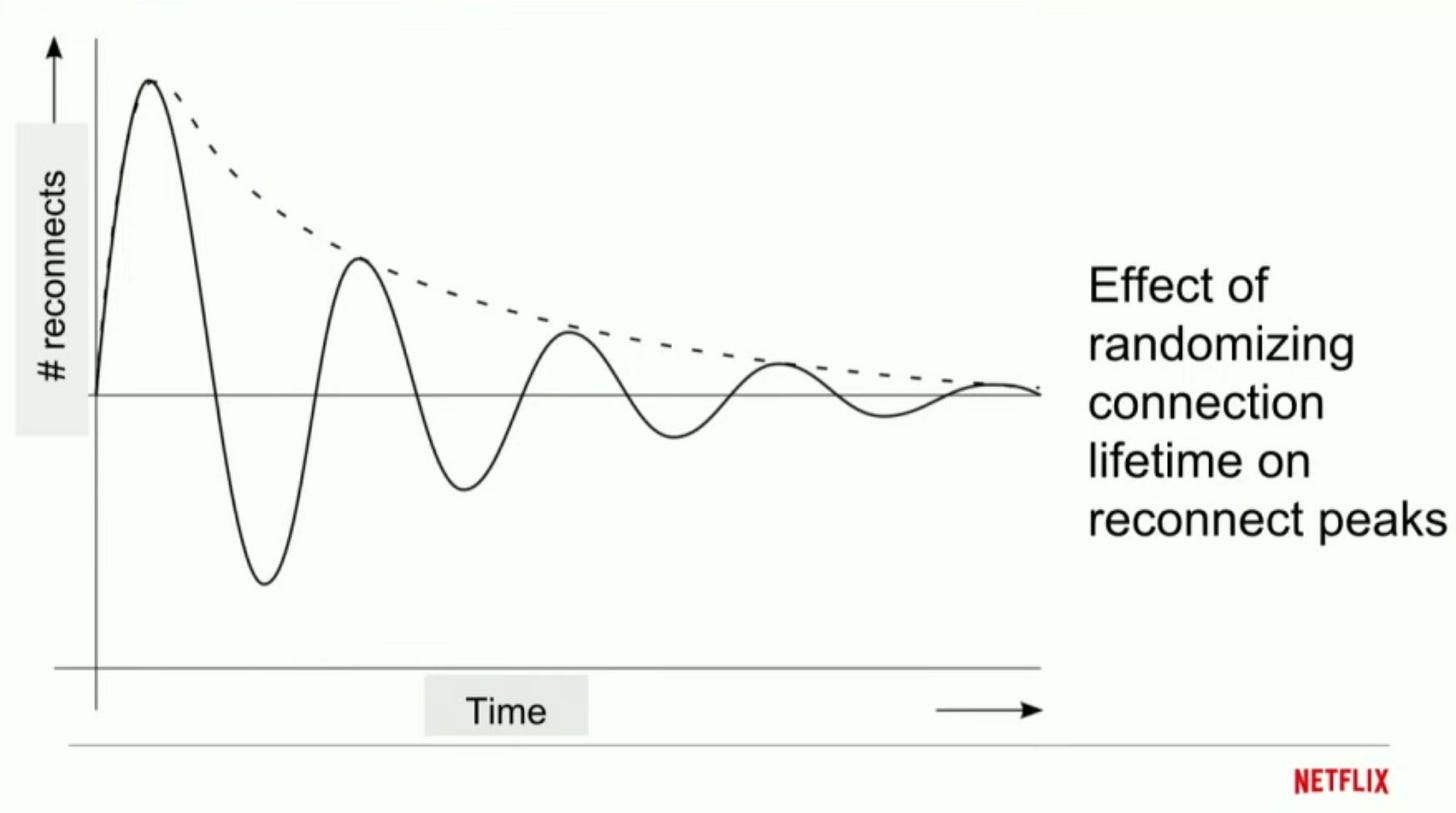
Randomization of connection timeout distributes number of reconnects over a period a time. It’s a very simple yet effective trick.Optimization: Ask clients to close its connection by sending a notification from the server side. The party whoever closes a
TCPconnection goes intoTIME-WAITstate (the final state in aTCPconnection life cycle). This state can hold file descriptors in Linux based operating system for 2 minutes. If the server closes the connection, there will be loads of file descriptors which need to wait for 2 minutes. This is expensive from server’s perspective. Hence, it’s better to initiate the connection closure from the client side so that server’s file descriptors can be saved.What if even after receiving the notification, a client does not close the connection? → To handle this scenario, the server starts a timer when it sends a notification to the client and wait till the timer is up. If the client still does not close the connection, the server forcefully closes it.
How to optimize Push servers? How to come up with the right number of push servers?
Most of the client connections were actually idle most of the time, meaning even if large number of connections are open to a server, the CPU and memory of those servers are not under any particular pressure. Essentially the machines were cold.
Knowing this information, they took few really big
EC2machine, tuned theTCPkernel parameters,JVMstartup options etc and they experimentally crammed it with as many as connections possible, just one of the servers crashed, all the disconnected connections came back in a thundering herd fashion. This was a problem because such a big machine used to handle thousands of connections and all of them came back almost together to reconnect. This did not work.They experimented again and used Amazon
EC2m4.large (8GB RAM, 2 vCPU)which is just right. With load testing and squeeze testing steps they figured out that with that particular server configuration, they can comfortably handle84kconcurrent connections and the system is comfortable losing few of such machines as it can handle that level of thundering herd given the expected production traffic.The lesson here is to optimize for the total cost of operation, not for low instance count. More number of cheaper server is better than large number of powerful servers as long as cost is justified.
How to auto-scale depending on the traffic?
RPS, Request Per Second and Average CPU load - these two usual strategies are ineffective for push cluster as there is no traditional request/response cycle and CPU is often idle.
The only limiting factor for push servers is - the number of open connections at any given point of time. So, it makes sense to auto-scale the push cluster based on number of open connections at any point in time.
AWS makes it very easy to auto scale on any metric as long as the metric is exported as custom cloud watch metric.
AWS Elastic Load Balances (AWS ELB) can not proxy web sockets.
The push cluster sits behind ELBs.
ELBs don’t understand the websocket upgrade request requested by the clients initially. They handle it as a regular
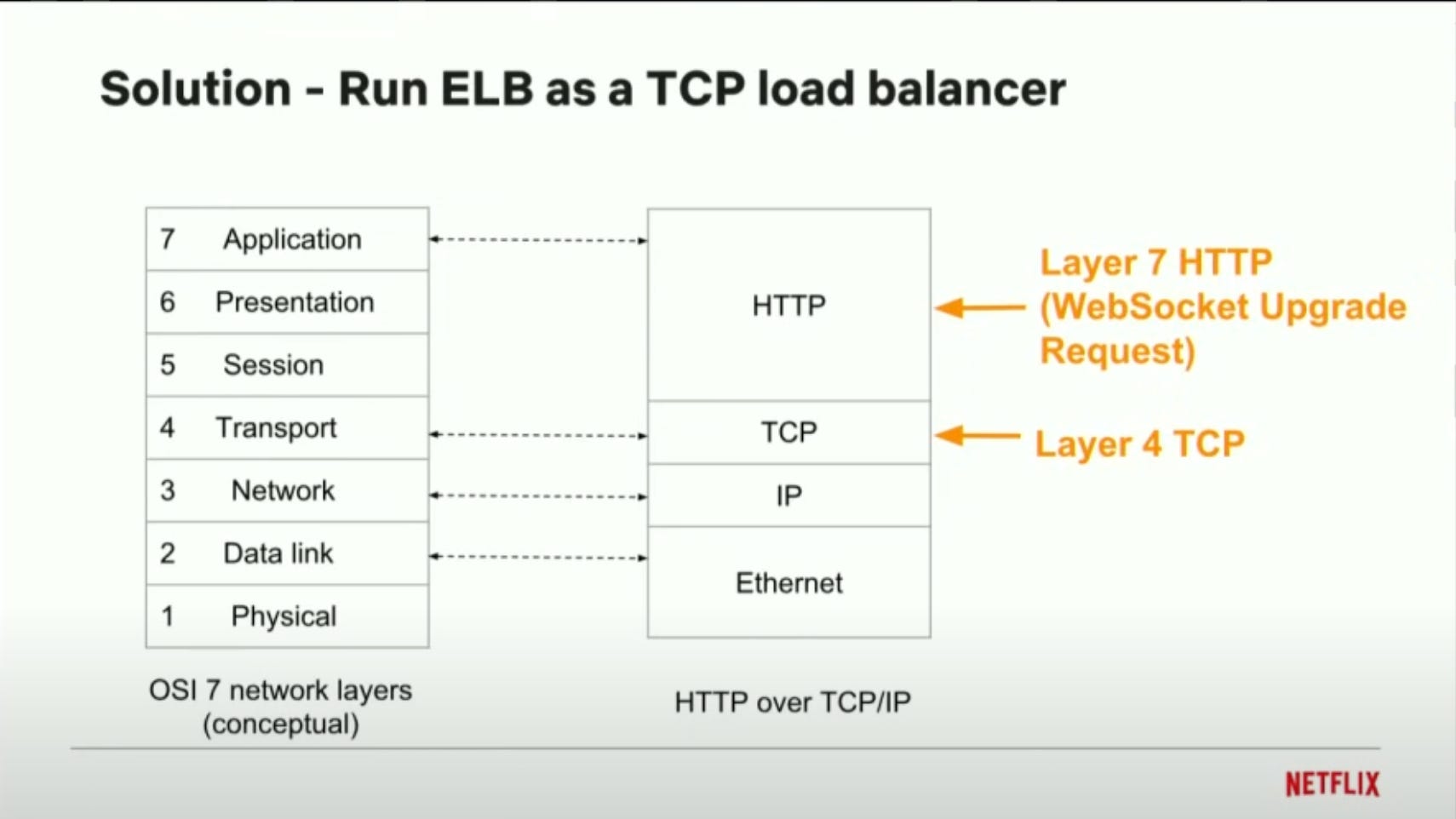
HTTPrequest which means as soon as the server returns the response, the connection is broken. Older version ofHAProxyandnginxas well don’t understand websocket protocol before they started supporting it.By default, an ELB runs as a Layer - 7 / Application Layer load balancer.
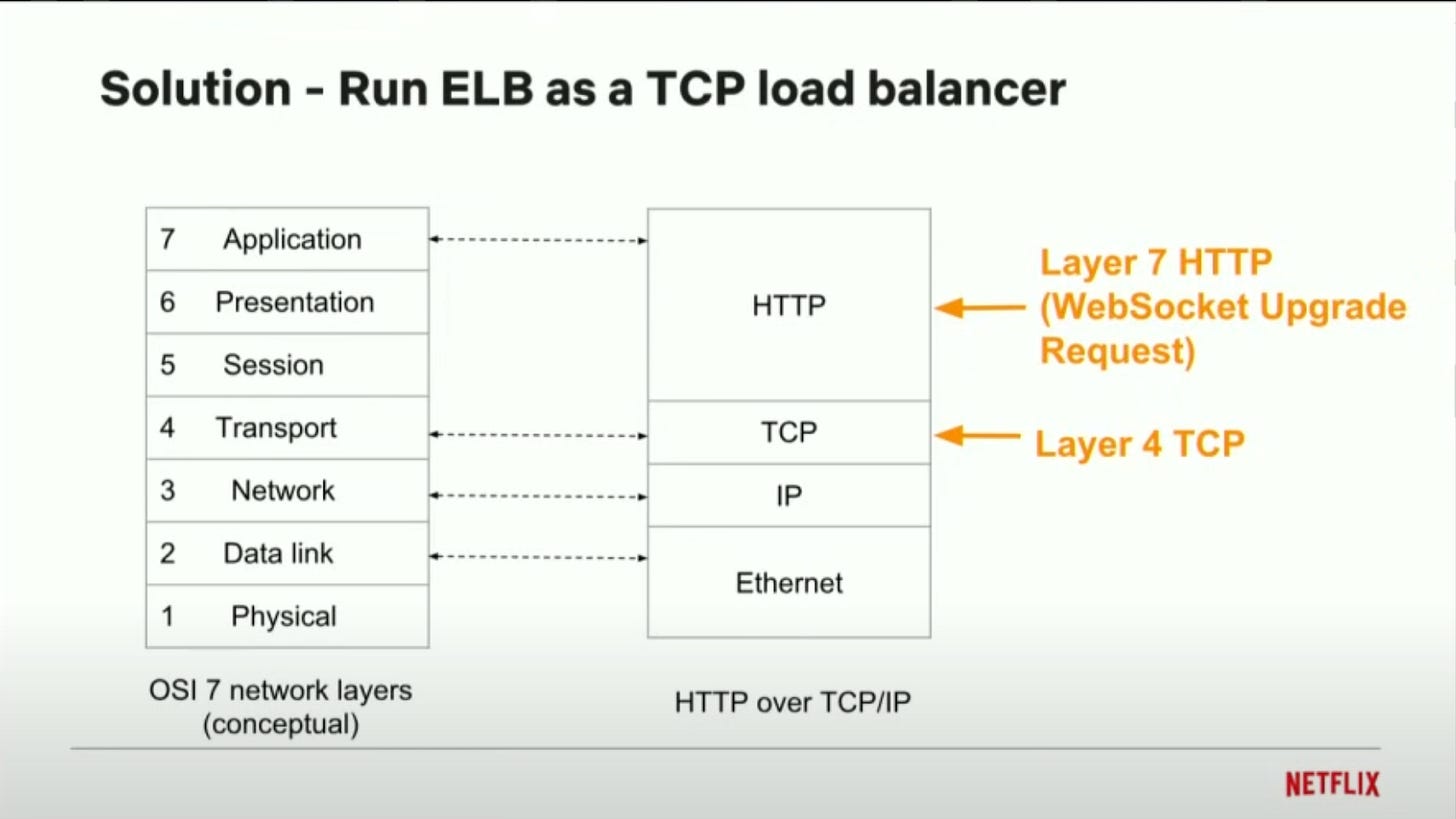
There is a configuration which flips it to a
TCPload balancer / Network load balancer that would work at Layer - 4. Network Load balancers don’t parse the application layer protocol, they just proxy the TCP packets back and forth.Amazon ALB (Application Load Balancer) natively supports WebSocket.
Miscellaneous
Every push message is coupled with some actions that the client can take and the server can track whether the clients took those actions.
Netflix relies on
A/B Test. They test the features on some percent of sample customers / devices in production and then they roll it out to100%of users.Clients typically send data in
JSONencoding to the server. However, the connection supports both text websocket frame and binary websocket frame. So, it’s possible to send binary encoded data too over the connection instead of text.Machine configuration =
8GB Ram, 2 vCPU. supporting84,000concurrent connections. But, to give some buffer, the servers usually contain72,000concurrent connections.Though Bi-Direction, WebSocket is mostly used to communicate from server to the clients. Most of the upstream API traffic is handled through regular
HTTPas that makes the servers stateless. For architectural reasons, there is nothing much to send from the clients to the server.What happens when closing a connection, a client loses some message? How to guarantee no message loss while clients are disconnecting? This can be handled by something called hand-over-hand websocket connections. While the existing websocket connection is open, the client can make a new websocket connection to another server. The new connection registry will override the old connection registry in the push registry as it’s designed this way. Once the new websocket connection is made, the old connection can be terminated.
Any push message delivery is Best-Effort basis delivery, it’s not a guaranteed delivery, but it works
99.9%often.Push servers themselves manage in-memory map of
client id (user_id, device_id or both)to connection object. When a message processor sends a message to a push server for a client, but the client no longer connected to the push server, the push server can return an error to the message processor saying the client is no longer connected or not found. On receiving the message, the message processor itself can delete the push registry for the client as it is no longer valid. Otherwise, anyway, when the client reconnects to another server, its push registry is re-written.Some of the messages are dispatched in batches to the clients.
De-duplication is handled at the client side as this is mostly application side logic.