
Real Life System Design: Change Data Capture for Distributed Databases @Netflix
Designing CDC at scale ...

Problem Statement
When a new movie is added to Netflix, the movie information is added to Cassandra database. There are many systems and applications which need to consume the new movie information for different use cases like analytics, data warehousing, recommendations etc. How do you stream the events from Cassandra to any other system inside Netflix?
Access Patterns
Different data stores solve problems for different access patterns:
Apache Cassandra (C*): It’s a highly available data store which supports high write throughput. But it does not support searching the data.
Elastic Search: Elastic Search can help search the data stored with full text search, fuzzy search etc but it does not do analytics well.
Data Warehouse: Data warehouse like Hive can can enable analytics, reporting etc.
So, what are different possible solutions to put every write operation across all these data stores?
Dual Writes: The problem is how do you reconcile if some write fails on one of the data stores?
Distributed Transaction: This needs coordination and management to be offloaded to some system outside of the databases which itself is a hard problem.
Separate Processes: Some process which would read data from the source database, optionally transform them and put the data to sink databases.
Verifier: The problem in this solution is that there needs to be some external verifier processes which need to verify if the data has been written successfully without any error to the sink databases.
Given all of the above problems, is there any alternative which can solve the problem comparatively easily?
Here comes Change Data Capture - CDC.
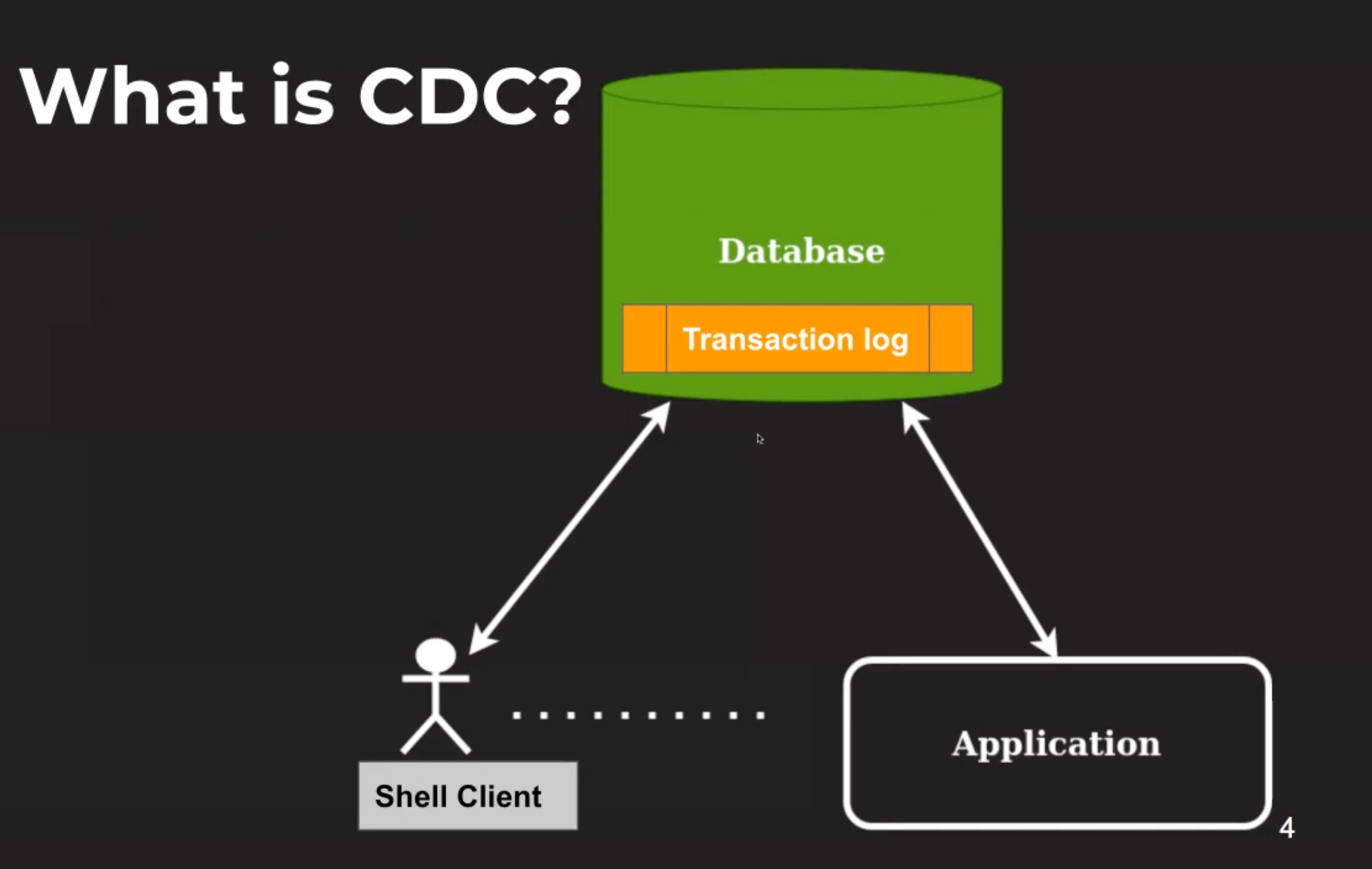
Databases receive mutations (insert, update, delete) from multiple sources like shell clients, applications etc. These mutations are captured in some form of transaction log inside the database. When we convert these changes to a stream of events, we have Change Data Capture (CDC) Stream. CDC captures changes happening in the source database and sends them to downstream consumers as a stream of events.
Some examples of CDC
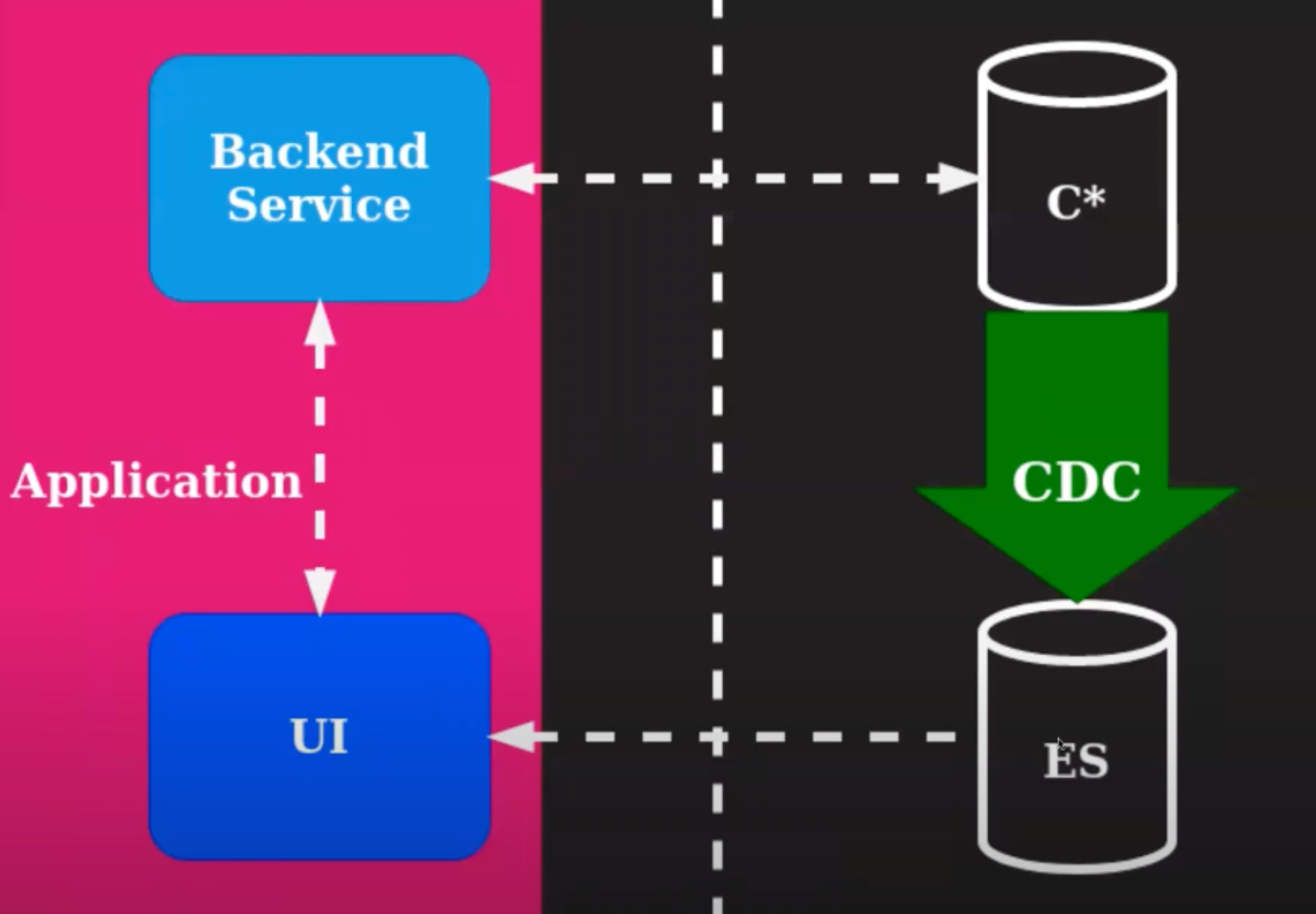
A backend application writes to Cassandra, the UI talks to the backend service. Also, the UI needs search enabled on certain fields to meet the user needs which Cassandra can not met. Thus Elastic Search comes into picture and the data sync between Cassandra and Elastic Search is solved by CDC.
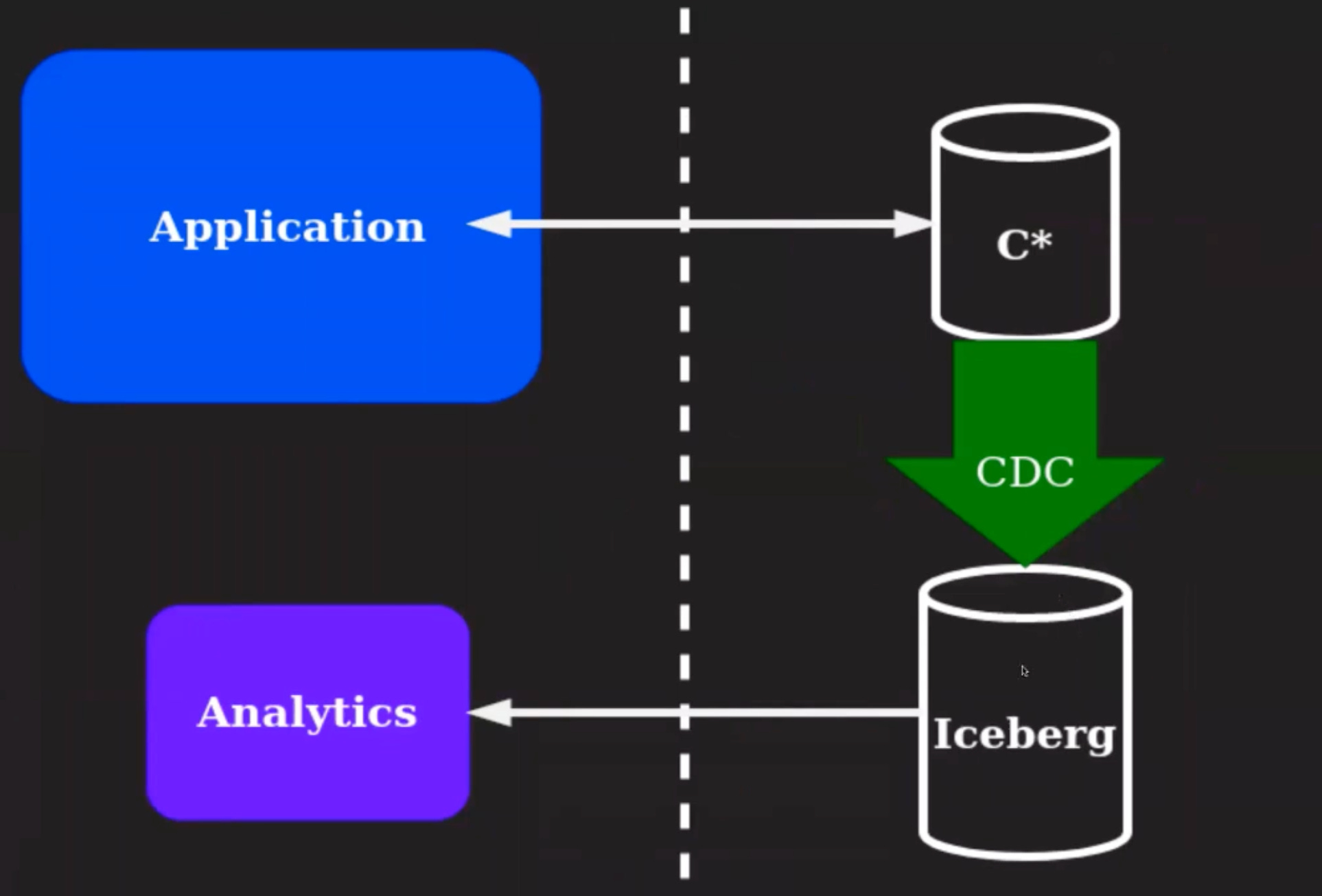
In this example, an application writes to Cassandra, and Analytics run huge queries, reporting etc on Iceberg / Hive like systems. So, how to sync data from Cassandra to Analytics system? CDC.
How CDC operates within Cassandra?
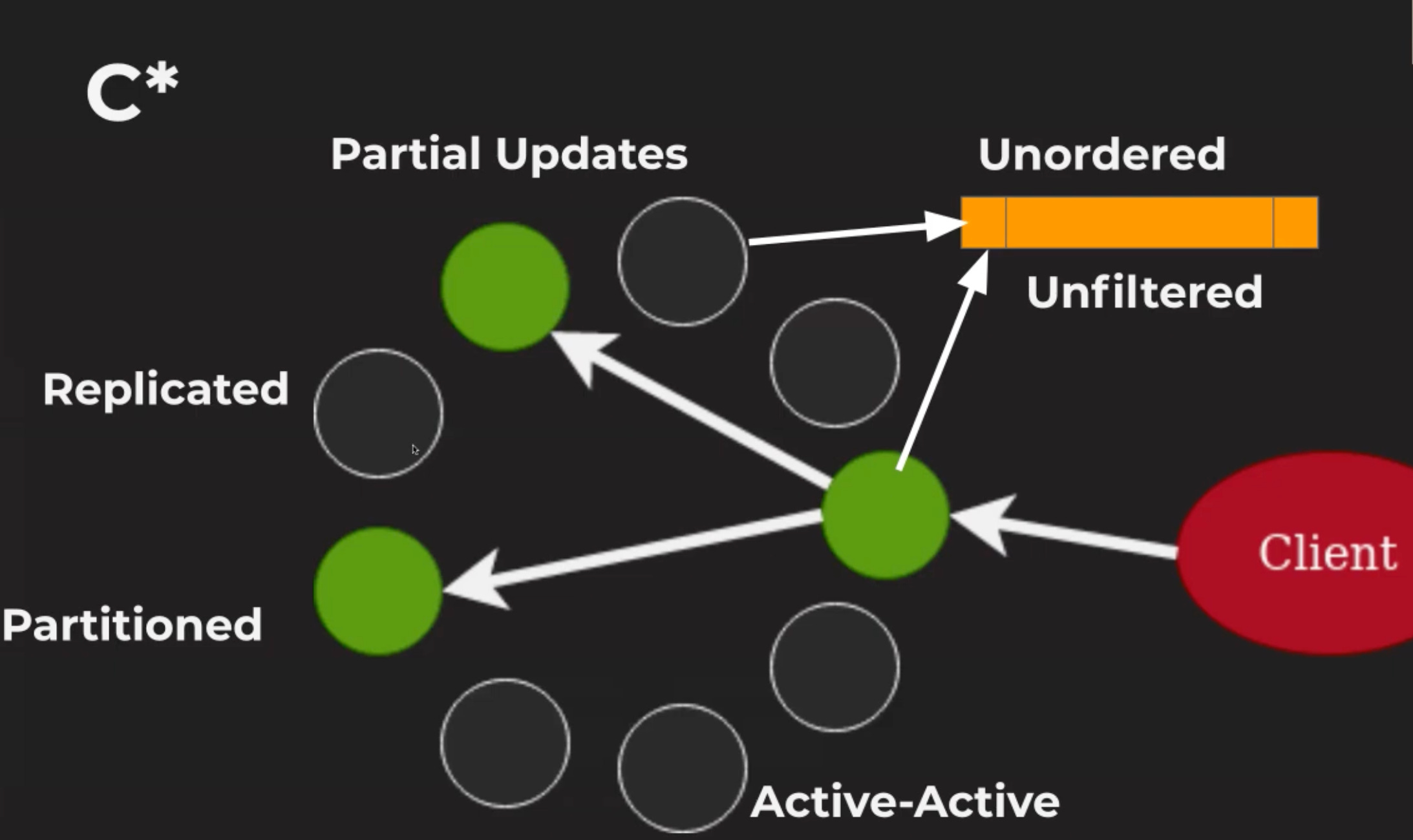
Cassandra provides high availability guarantees by having 3 replicas across different nodes of a cluster. Performance is generally good despite the replication. What are the challenges in such a system?
The data is partitioned. So, multiple nodes have to emit the change stream.
The data is replicated which means the same change will be emitted by multiple nodes.
The system is Active-Active meaning there is no single authoratitive node to get the change stream unlike databases like MySQL or Postgres.
When writes from multiple replicas enter the change stream, there is no ordering guarantee of the writes of the stream. The stream is unfiltered - all changes happening across the cluster are part of the change stream, there is no filter on which column family the change belongs to or what the columns the user would be changing.
Cassandra only provides partial changes - updates and deletes contain only affected columns and keys, but not details about the full impact.
A change stream with these properties ends up requiring downstream systems which consume this to make sure that they are deduplicated and have ordering somehow, and filter them according to their requirements. This is an issue with the open source Debezium Cassandra connector also.
Change Stream Properties
Uniqueness: There should be no duplicate changes.
Ordered: The changes that are emitted, they are emitted in the order that they got committed in the source database.
Full row images: They have full row images. All columns, including pre and post images of a row are emitted in the stream.
Filtered: It should be filtered, so that there is a change stream per database per table and specific columns might need to be filtered out for security requirements, where the columns could contain personally identifiable information, which should not be leaving the boundaries of the database cluster.
Possible Solutions
Incremental Backups: The Cassandra clusters at Netflix have incremental backups where
SSTablesfrom the cluster are written toS3at regular intervals. The backup system is robust but this approach could take minutes to hours to emit changes. It's not near real-time, which is a core requirement.Audit of Full Query Loggers: This would end up severely degrading the cluster performance and require changes to Cassandra. It also needs ordering to be recreated outside of Cassandra.
CDC in Coordinator: This has issues with having availability and continuation of the change stream when the coordinator goes down and there's a newly elected node which becomes the coordinator.
CDC in additional copy: An additional Cassandra node can be put in the asynchronous write path, but not on the read path and it will capture all the change streams from the Cassandra cluster where it is put. This will ensure that the change streams are captured following the above properties. But it’s very complex to implement as it require major changes into Cassandra.
Solution
Netflix’s solution introduces an intermediary system that would make sure that events in the stream are unique, ordered, full row images and filtered.
System Design
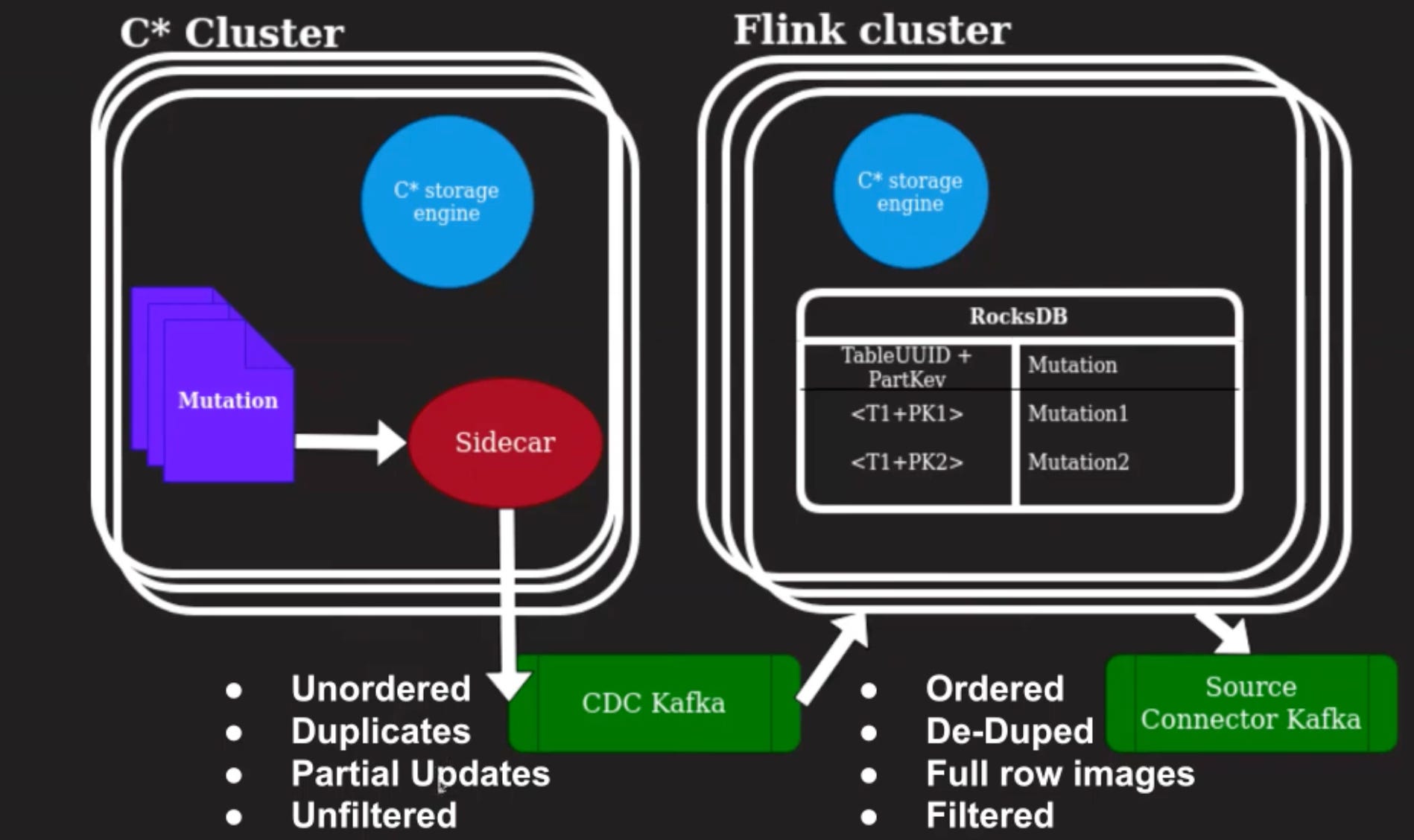
The mutations are read from the commit log of Cassandra, and written to a Kafka topic.
Flink application and the Cassandra cluster need to have the same versions of the Cassandra storage engine to be able to read objects correctly - this is required to generate the correct full row image.
Flink uses a KV Store (RocksDB) to store data and make sure that the Cassandra output which is unordered, has duplicates, has only partial updates, and is unfiltered, can be converted to one which is ordered, dedupe created, has full row images, and is filtered.
System Properties
Input Processing: The output of the Cassandra cluster ends up being a Kafka topic with
npartitions. Workers process events on each partition. Having this intermediary Kafka topic decouples the availability of the consuming system. This also ensures that the CDC solution has minimal impact on the Cassandra clusters performance.Linearizable Datastore: The system has a linearizable datastore to retrieve the most recent information, which is stored for a particular partition key, if present. Apply the incoming change, and write that back into the datastore. This helps achieving the same ordering which is given by Cassandra for its clients.
Scaling: The system can be scaled independently from the Cassandra cluster to account for changes in the stream rate.
Open Sourcing: The system can be open sourced.
Apache Flink
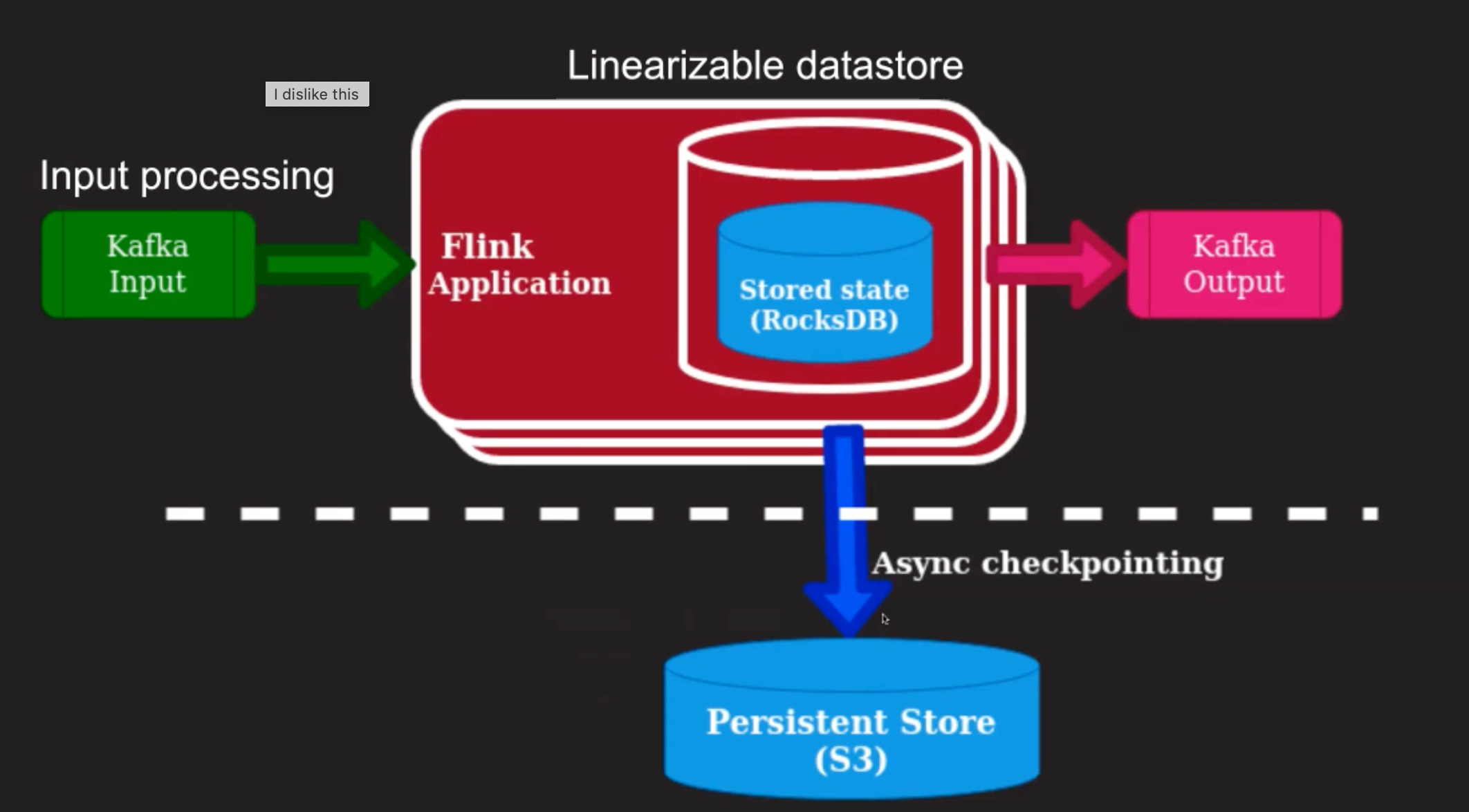
Apache Flink is a streaming system which acts as a data plane in this system.
The Flink application reads from the Kafka topic.
The application itself maintains state, which is RocksDB in this solution, an ephemeral in-memory datastore.
The incoming data is processed and emitted to the output Kafka topic.
The Flink application is able to process the stream of data and recover from failures by having the stored application state and Kafka offsets, check-pointed at regular intervals.
The Flink application can scale independently of the Cassandra cluster.
How is this intermediary state is leveraged to provide a CDC solution for Cassandra?
Create Flow
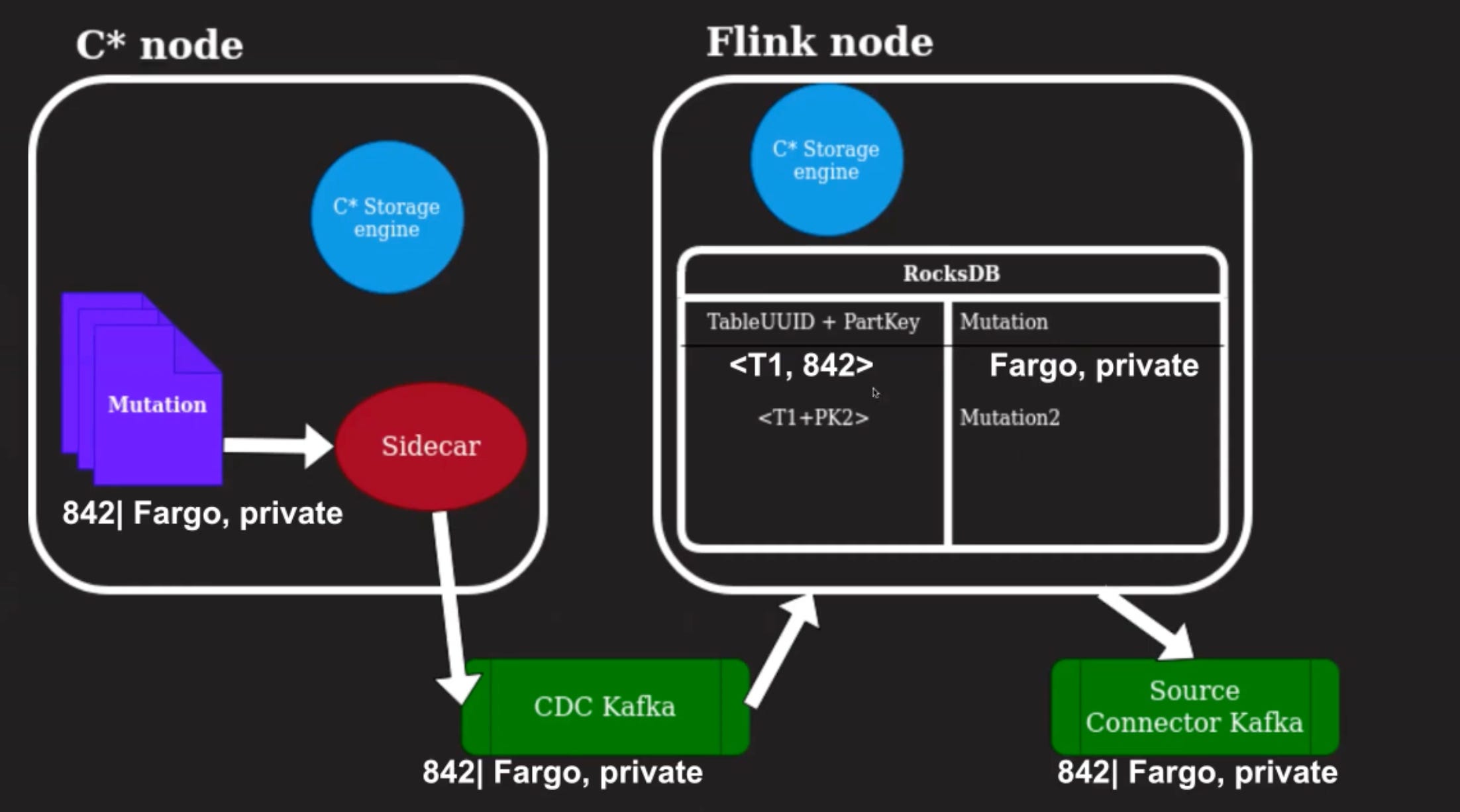
Let's look at this with an example.
Let us say there is a new movie being written into the database with a movie ID, 842, for Fargo, and the status is private.
The sidecar would read this mutation and write it to the CDC Kafka topic.
This would then end up being read by the Flink application and written into the RocksDB store with the partition key and the mutation information.
As this is a fresh show, it would have all of the information for that particular row.
The second Kafka topic then gets a record for that row with a Create operation. As you can see here, a fourth copy of the data is maintained outside of Cassandra. Why this would be required?
Update Flow
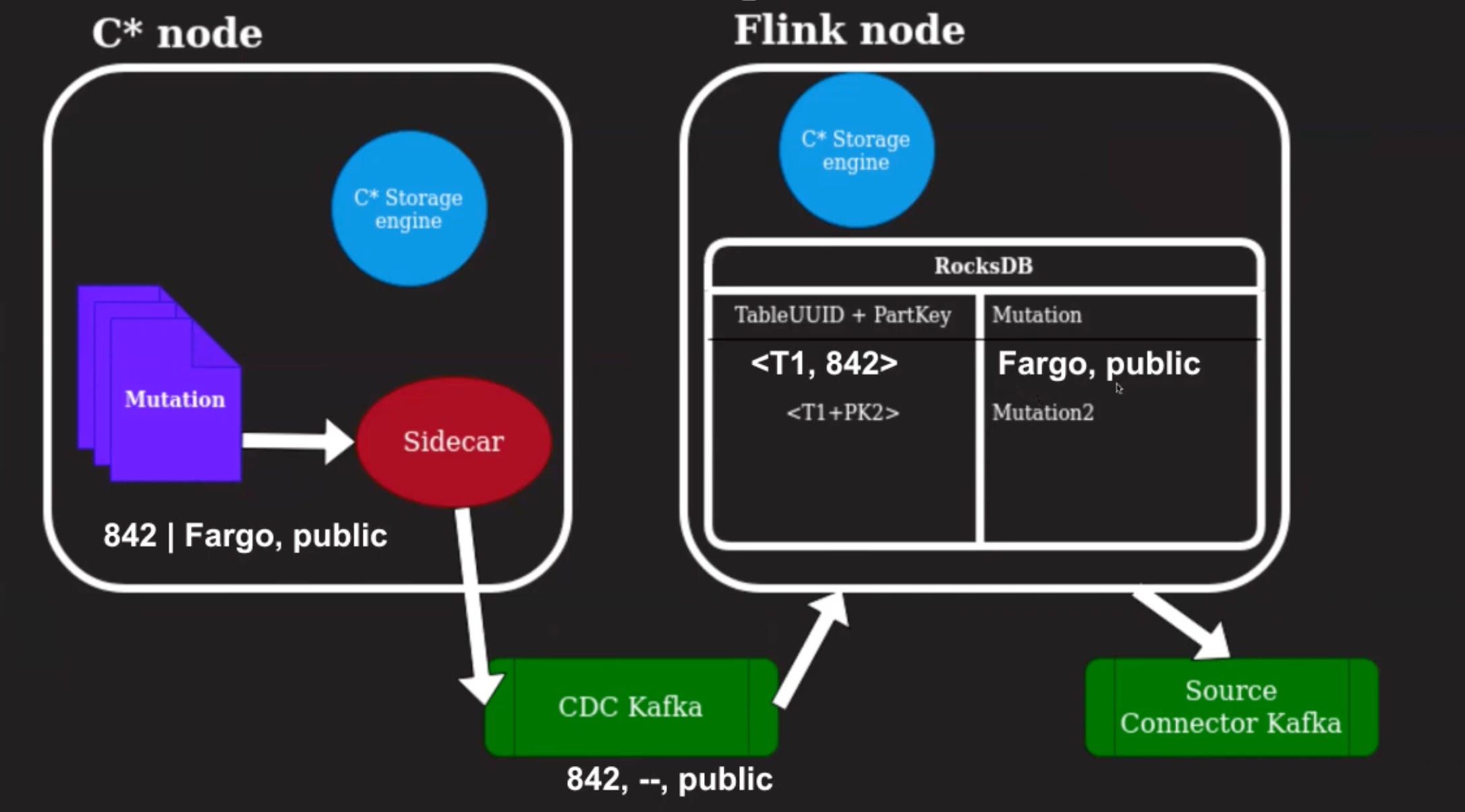
Let's update that row to have different information in the columns.
We want to change the status of Fargo from private to public.
When we make that update in Cassandra, the sidecar emits that change to the CDC Kafka topic. It is important to note that the change in the Kafka topic only has to change columns but not all of the row information. Specifically, we are missing the information that Fargo is part of the store.
When this is sent to the Flink application, we have the previous mutation which came for this particular partition key, and we can reconcile that with the incoming event and make sure that we have a full row image generated in this datastore.
This is then emitted as an update for that particular row into the Source Connector Kafka.
Delete Flow
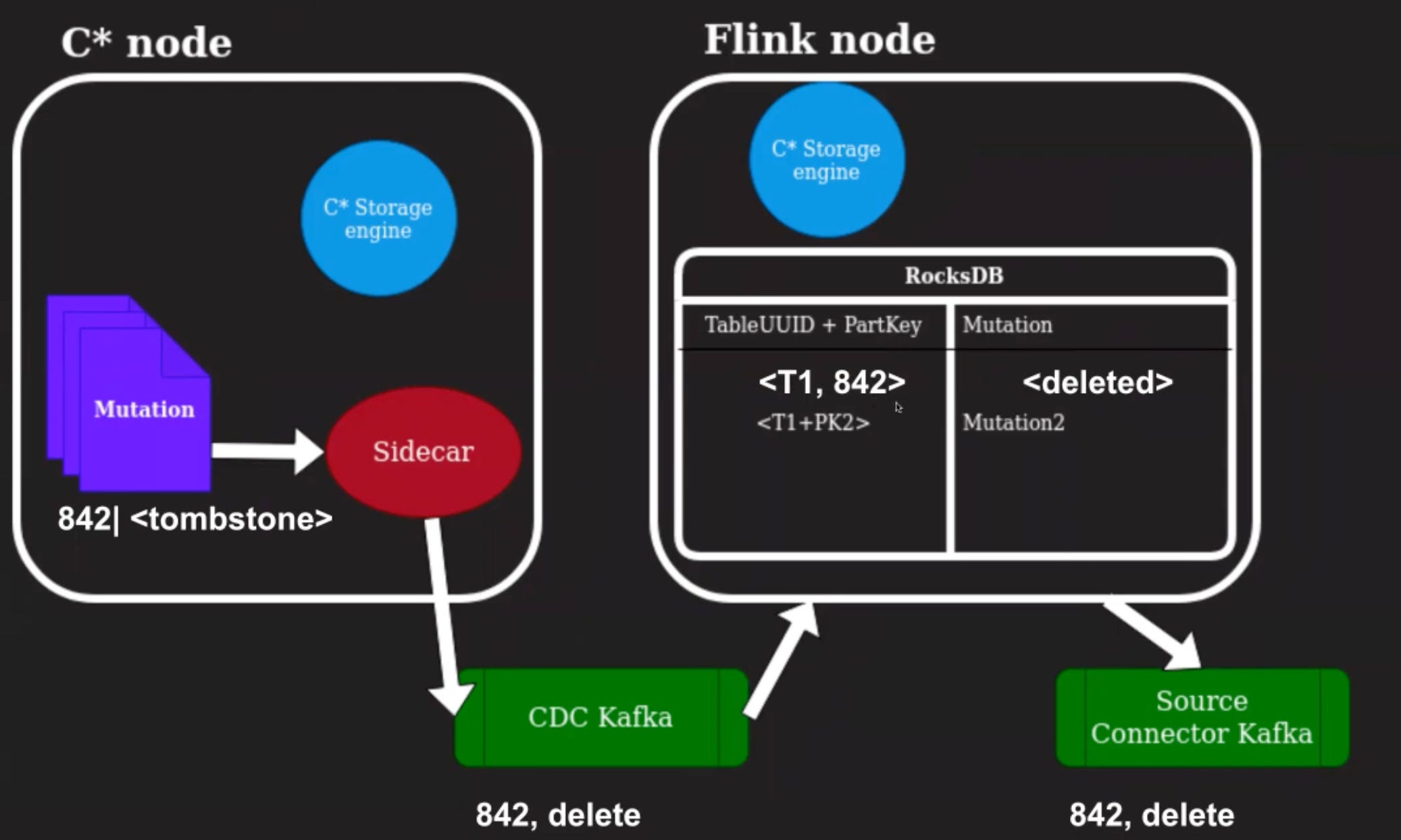
Let's look at how a delete would happen.
If we end up deleting that same row from Cassandra, we store a delete for that particular partition key in Cassandra as a tombstone. Cassandra would end up removing this tombstone after GC, 3seconds.
The sidecar would serialize this mutation, and we would store that particular delete within the datastore here and emit the delete information to the Source Connector Kafka.
We also, at the same time, store a timer within Flink state to make sure that we remove this partition key from the map, if there are no future updates, which come for this particular partition key with a higher timestamp.
This way, we can make sure that the data grows and shrinks correctly, according to whatever is happening on Cassandra.
Uniqueness and Ordering
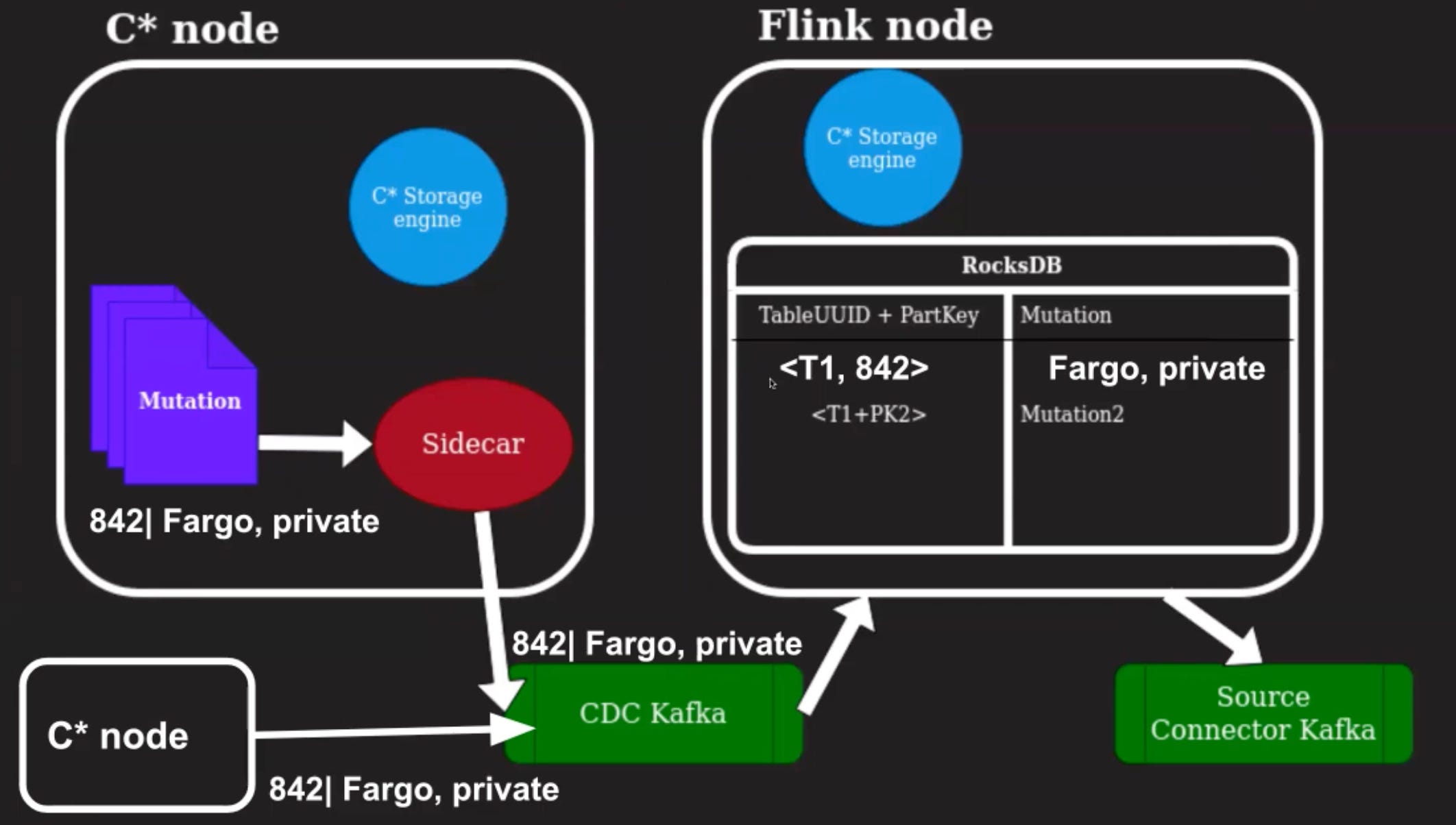
How do we make sure we can guarantee uniqueness and ordering in our output stream?
Unique mutations in the Source Connector Kafka stream can be achieved by checking that we have already processed this particular information from a previous replica. When the second replica ends up emitting this same information, we do not send the row update to the Source Connector Kafka.
Ordering is guaranteed by making the CDC Kafka topic a key topic where the key is the partition key of the change. This way, all changes for a particular partition key arrive at the same consumer in Flink. Because we have the same storage engine, we can recreate order for these changes correctly.
There is a cost to be paid for the ordering, we would need to deserialize the mutation to know which partition key to use, and serialize it back before writing it to the CDC Kafka topic.
Schema Changes
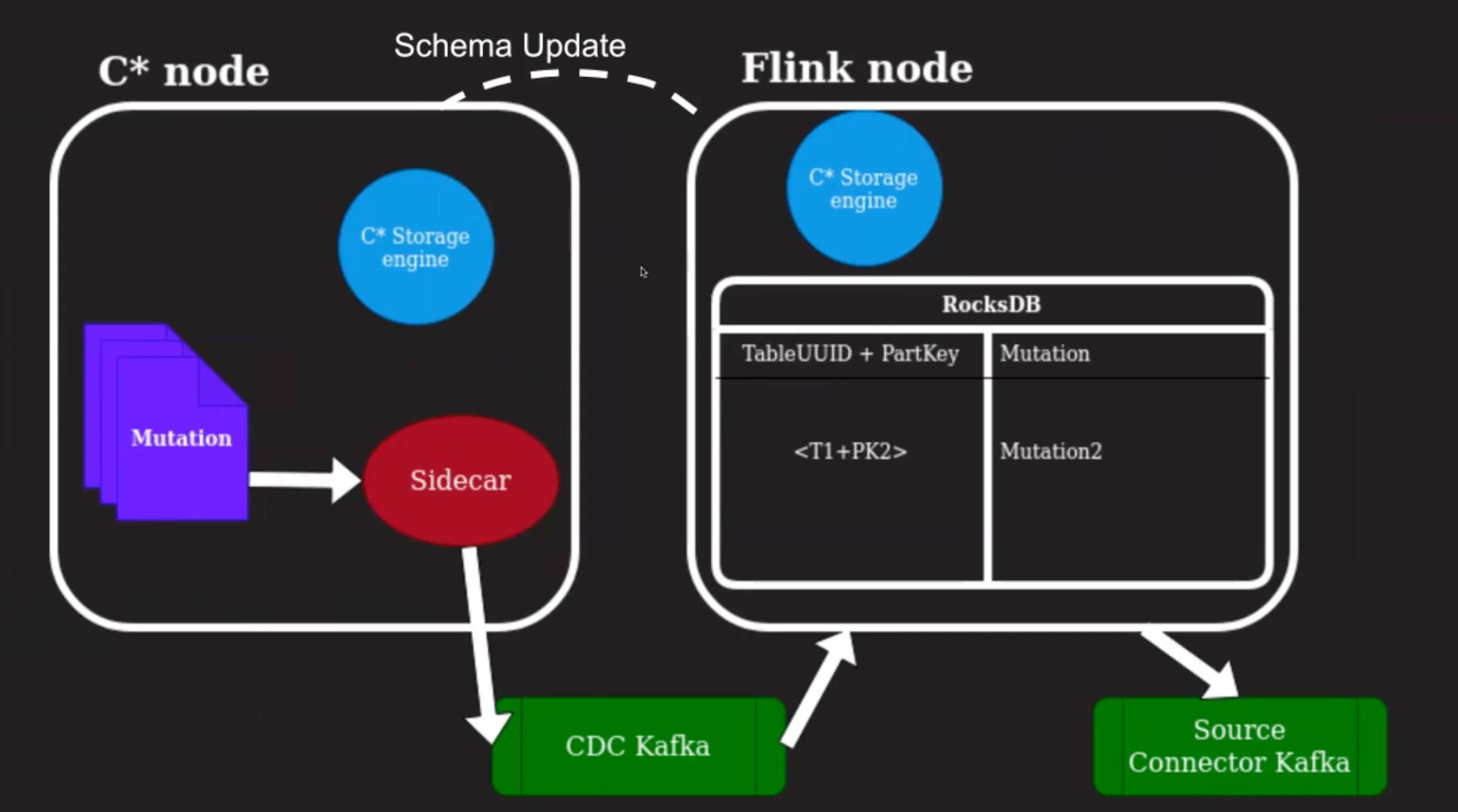
What happens when the schema for column family changes?
The Cassandra storage engine in Flink needs to have the right schema information in order to deserialize the mutation correctly. For this, we listen for schema changes by registering with the Cassandra cluster to make sure we have this up to date information.
Filtering
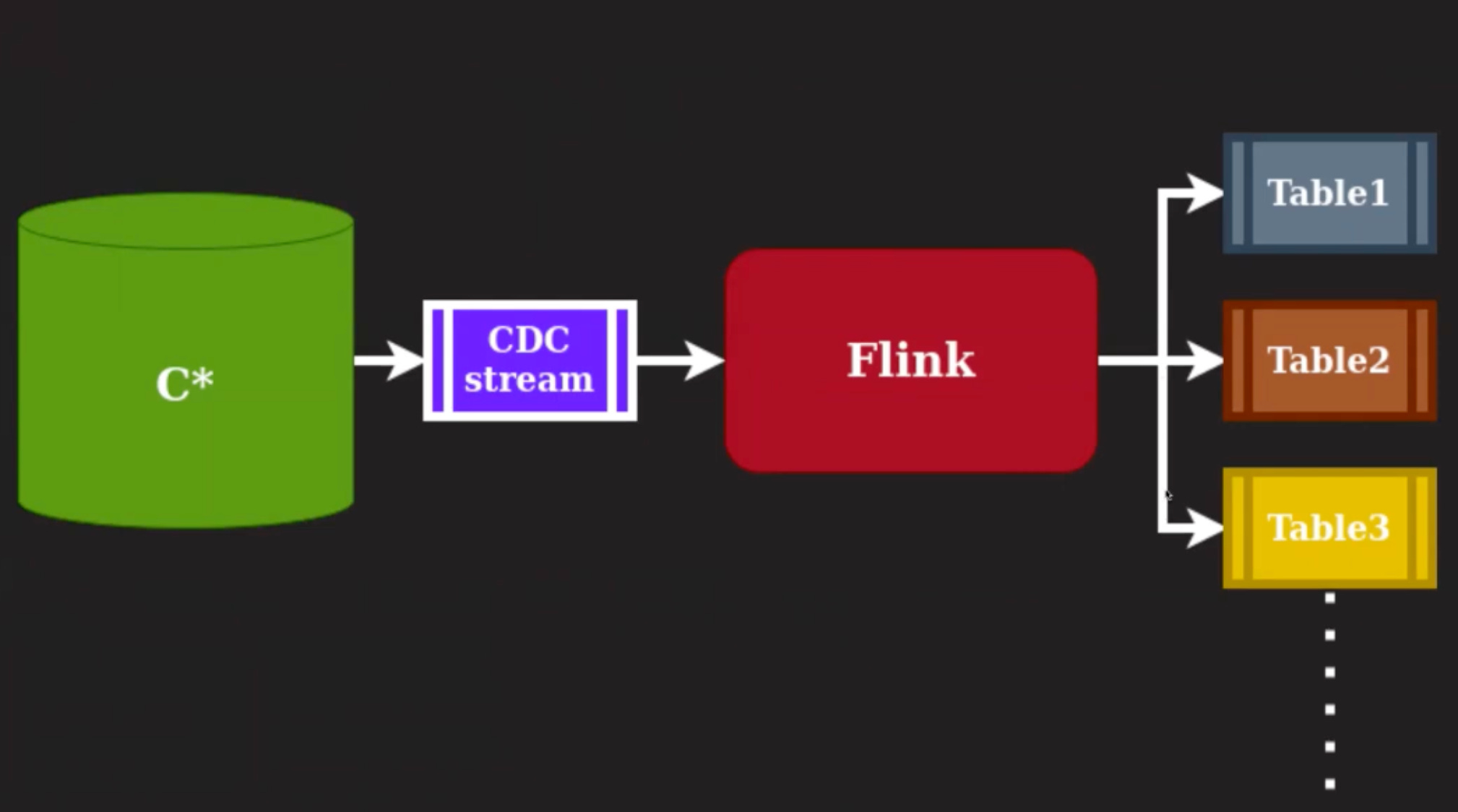
How do we make sure we have filtering of the output Change Data Capture stream?
This is required because the original CDC stream from Cassandra will have changes from all of the column families or tables for that particular cluster. We would normally want this as separate streams and with specific fields. We can perform this filtering at the Flink application and generate messages to multiple Kafka topics, one per column family.
Challenges
What are some challenges with this solution?
Additional copy of data: There is an additional copy of the data, so if the replication factor is already three for Cassandra resiliency, then there are four copies. This added cost is on both infrastructure and maintenance.
Write throughput on C* > Kafka production: What happens when the write throughput on Cassandra is higher than what Kafka can safely handle? We could drop the stream to keep Cassandra available.
Backfill from SSTables: The above would mean we need to backfill from SSTables at scale.
C* Storage Engine Compatibility: We would also need to make sure that the Flink system and Cassandra cluster which is emitting changes are the same version of the storage engine, which is also an operational overhead.